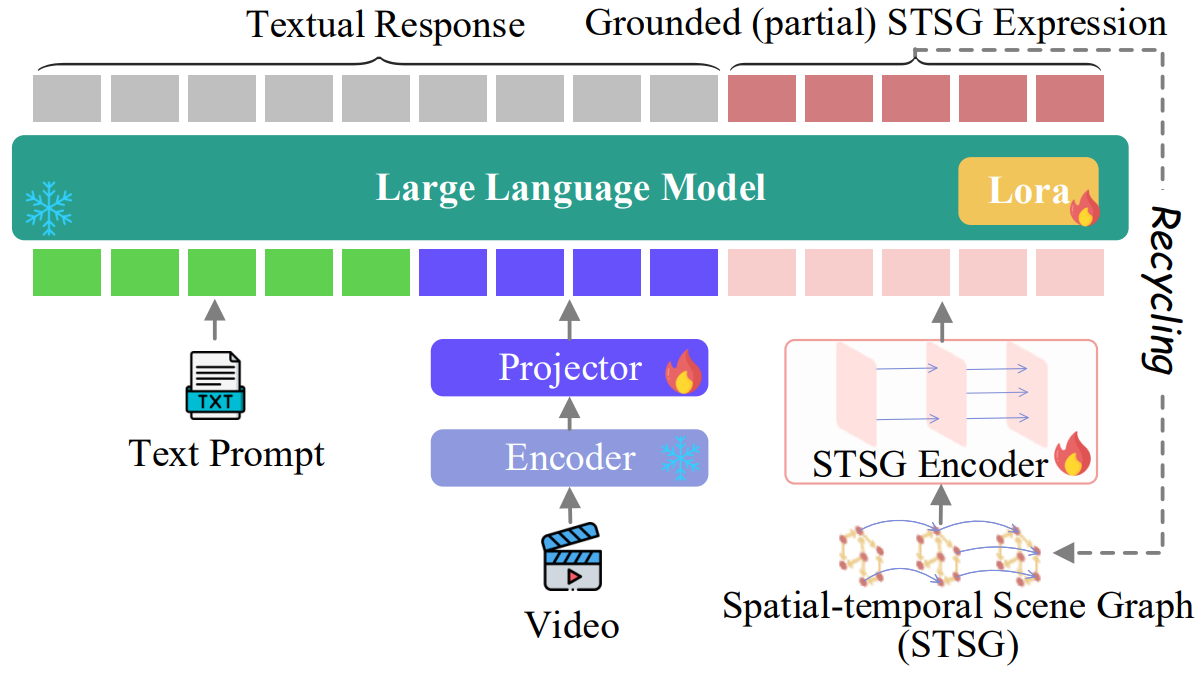
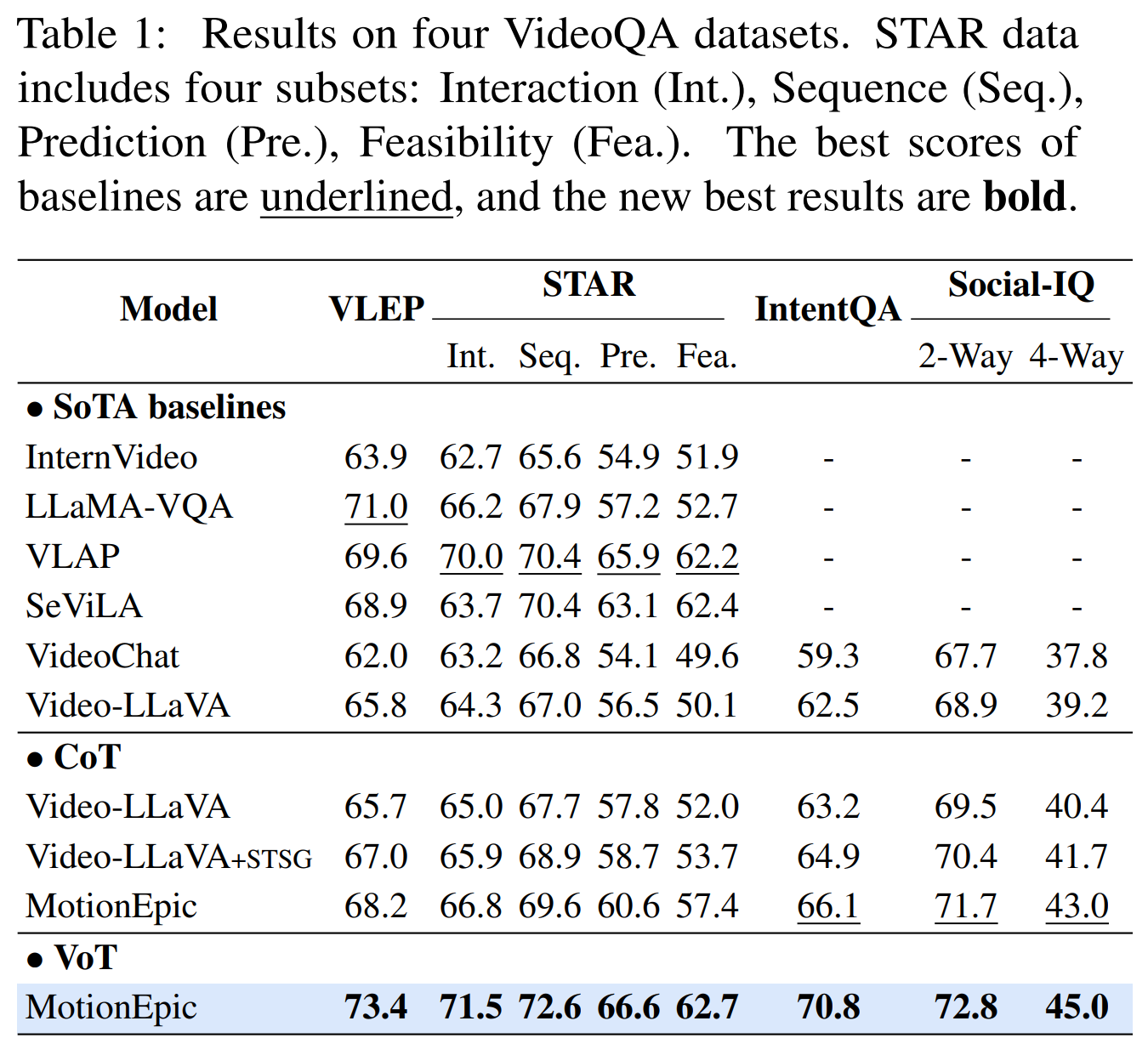
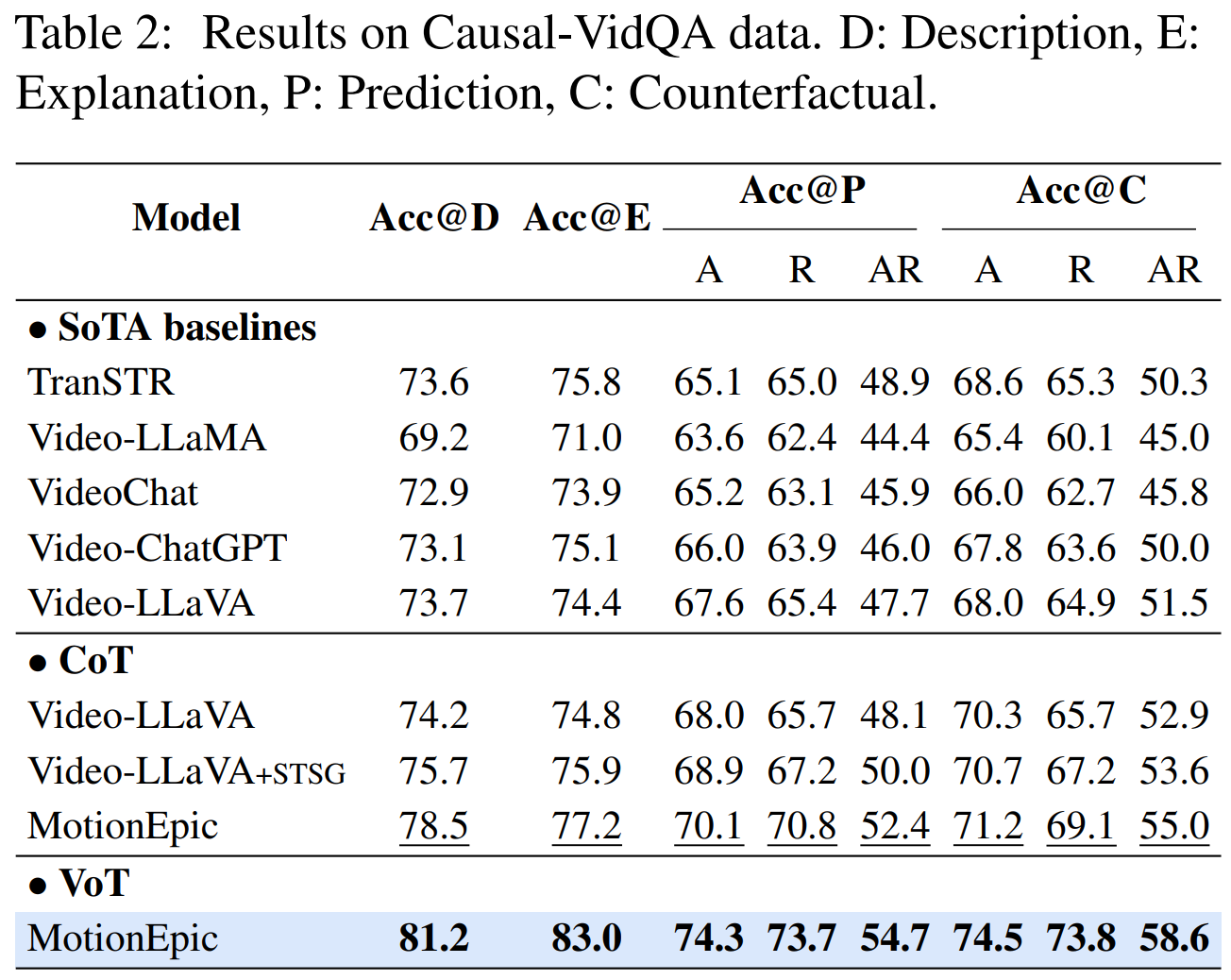
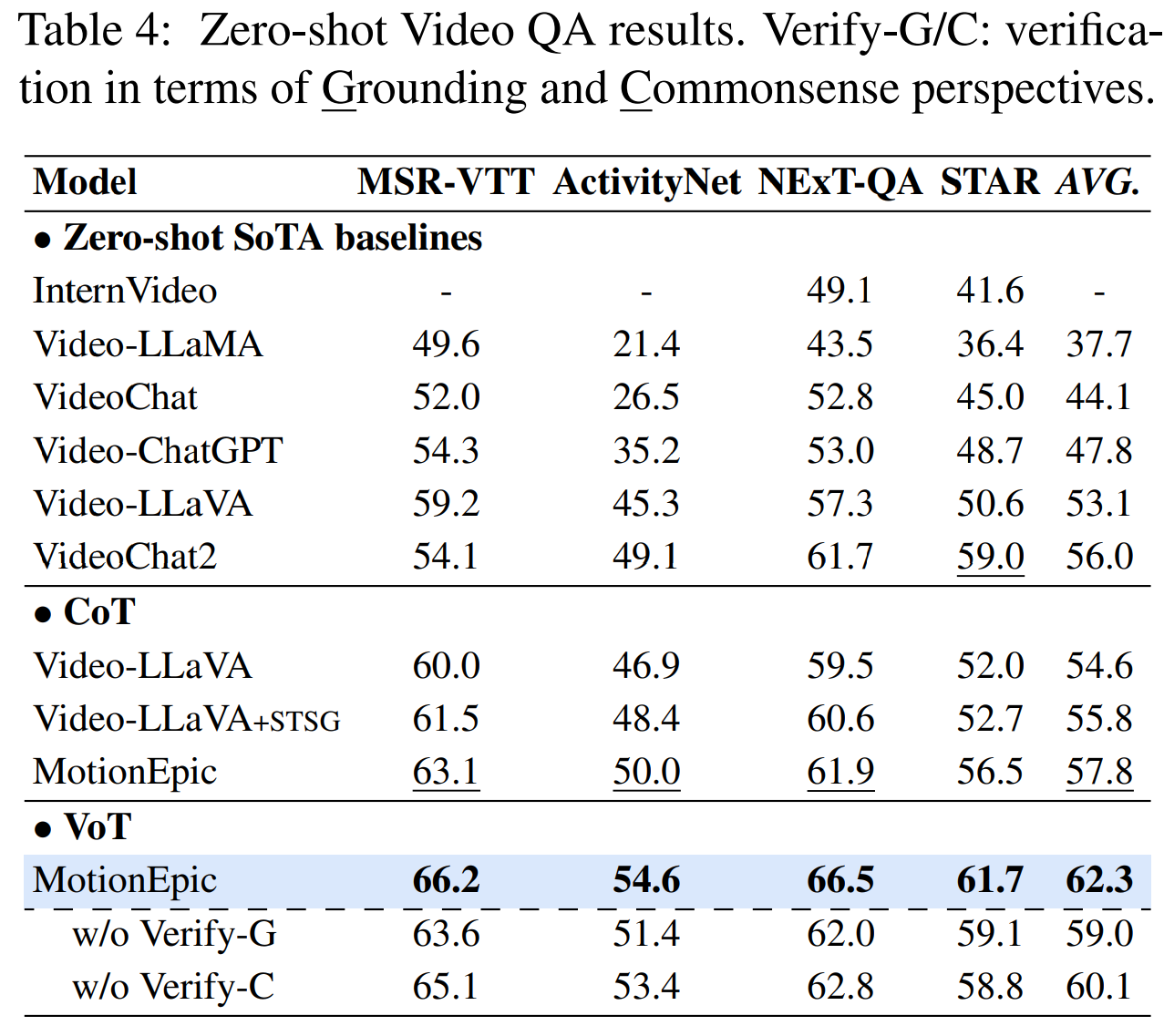
Video-of-Thought (VoT)
Video Reasoning Framework

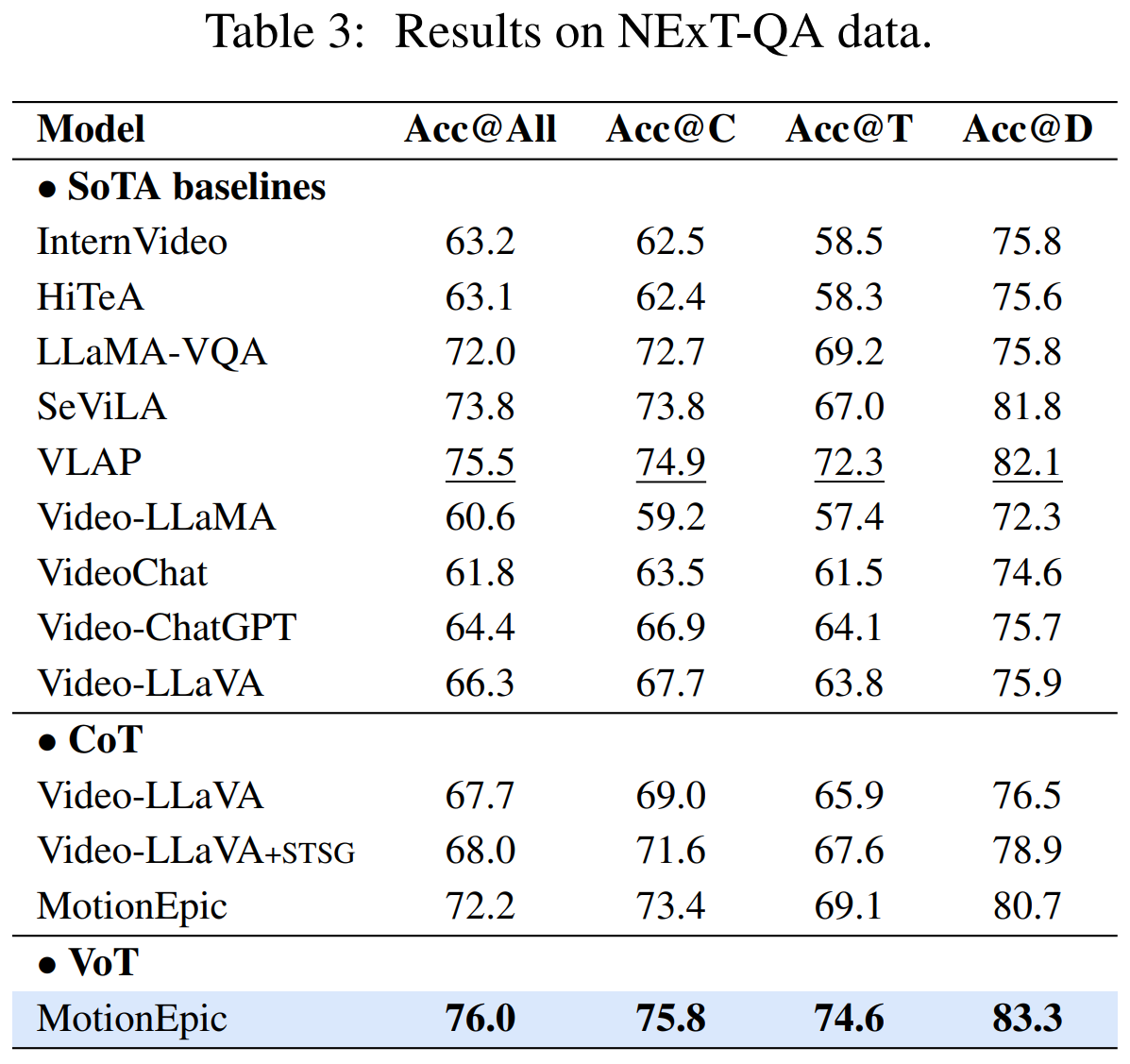
Given an input video and a question, VoT identifies the possible target(s) involved in the question to observe.

After this step, all the possible Target involved in the question will be confirmed.
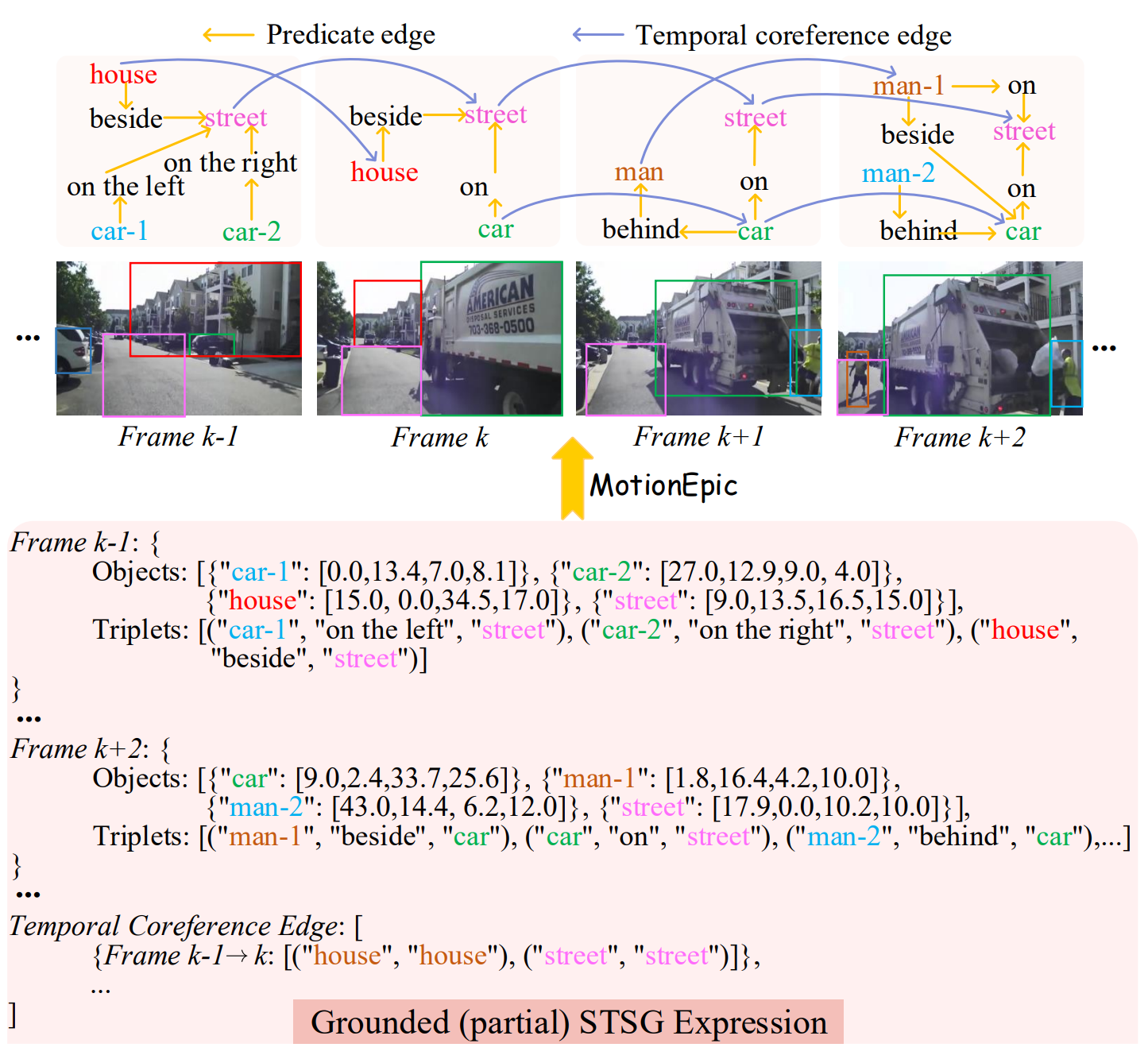
The system then grounds the temporal tracklet(s), which serves as supporting evidence/rationale for content perception in subsequent analysis.

The yielded grounded Target Tracklet of STSG will serve as low-level evidence (i.e., supporting rationale) for the next step of behavior analysis.
Combined with factual commonsense, VoT next interprets the target object's trajectory and its interactions with neighboring scenes to thoroughly understand the action dynamics and semantics.

This step yields the target action's Observation and Implication.
With in-depth understanding of the target actions in the video, we then carefully examine each optional answer with commonsense knowledge, where the final result is output after ranking those candidates.

We then rank the scores of all options and select the most optimal answer Answer.
Finally, VoT performs verification for the answer from both pixel grounding perception and commonsense cognition perspectives, ensuring the most factually accurate result.

If any inconsistencies are found in perception and cognition perspectives, we record the corresponding rationale, and re-execute the 4-th step to reselect the answer. This approach ensures that the final outcome is the most factually accurate.