Motivation
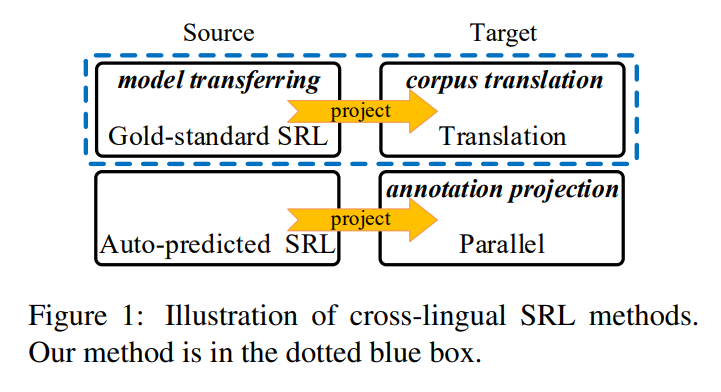
Model transferring and annotation projection are two mainstream categories for the cross-lingual transfer learning. The former builds cross-lingual models on language-independent features such as cross-lingual word representations and universal POS tags which can be transferred into target languages directly. The latter bases on a large-scale parallel corpus between the source and target languages where the source-side sentences are annotated with SRL tags automatically by a source SRL labeler, and then the source annotations are projected onto the target-side sentences in accordance of word alignments.
The annotation projection can be combined with model transferring naturally, where the projected SRL tags in annotation projection could contain much noise because of the source-side automatic annotations. A straightforward solution is the translation-based approach, which has been demonstrated effective for cross-lingual dependency parsing. The key idea is to translate the gold-standard source training data into target language side by translation directly, avoiding the problem of the low-quality source annotations.
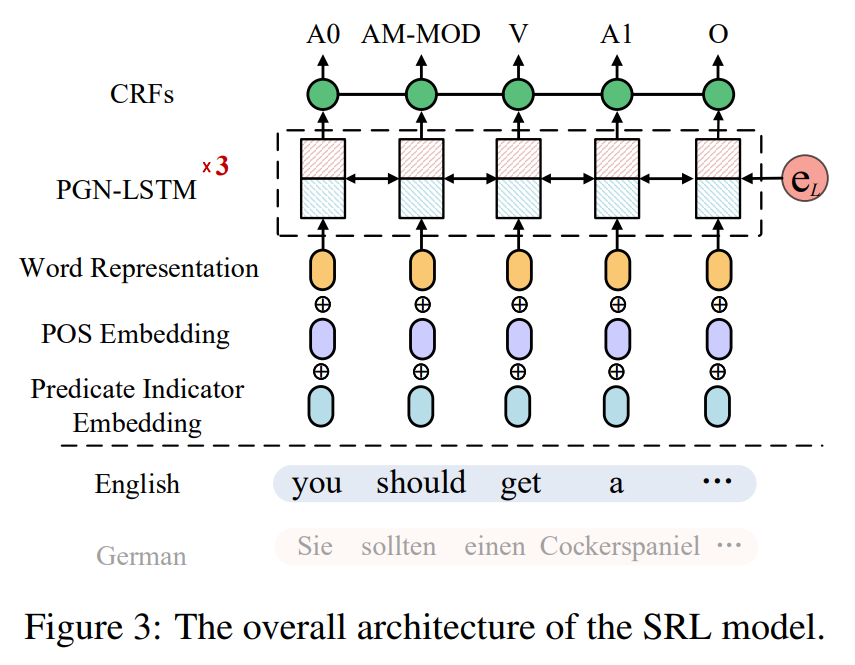
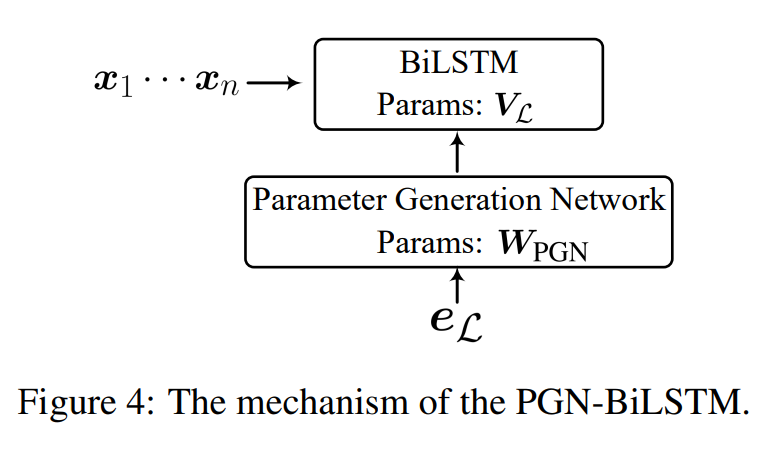
In this project, we study the translation-based method for cross-lingual SRL. Sentences of the source language training corpus are translated into the target language, and then the source SRL annotations are projected into the target side, resulting in a set of high-quality target language SRL corpus, which is used to train the target SRL model. Further, we merge the gold-standard source corpus and the translated target together, which can be regarded as a combination of the translation-based method and the model transferring.