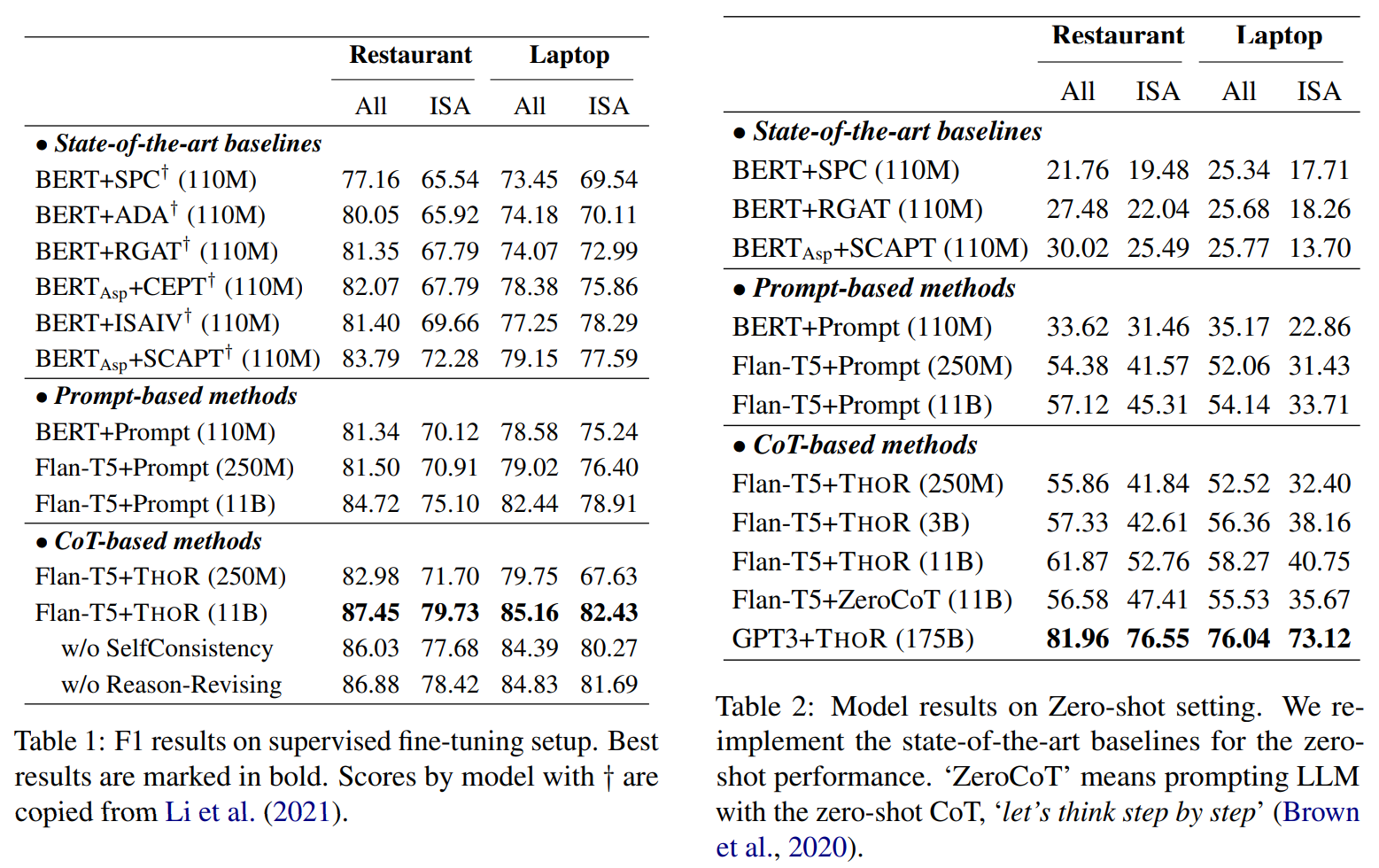
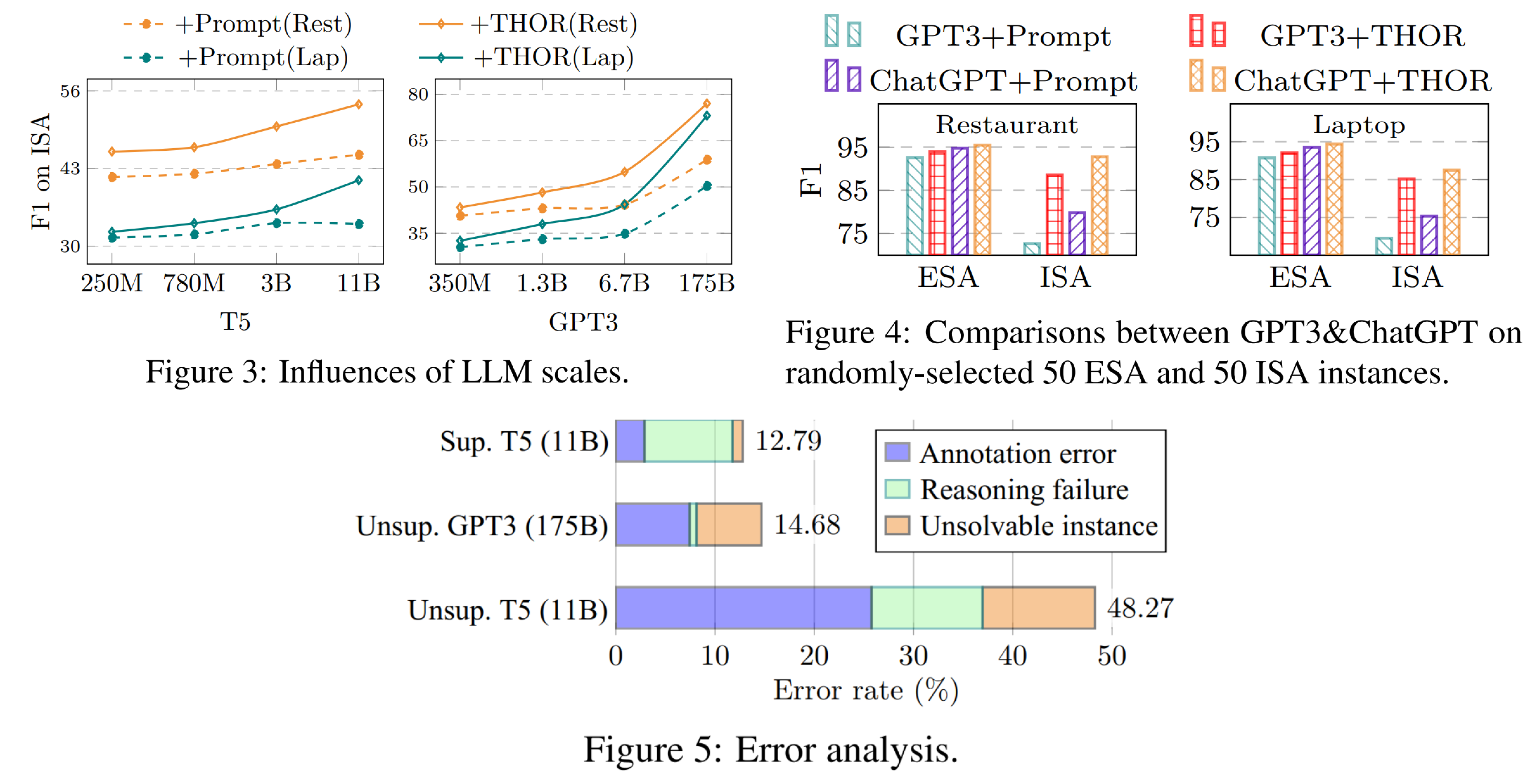
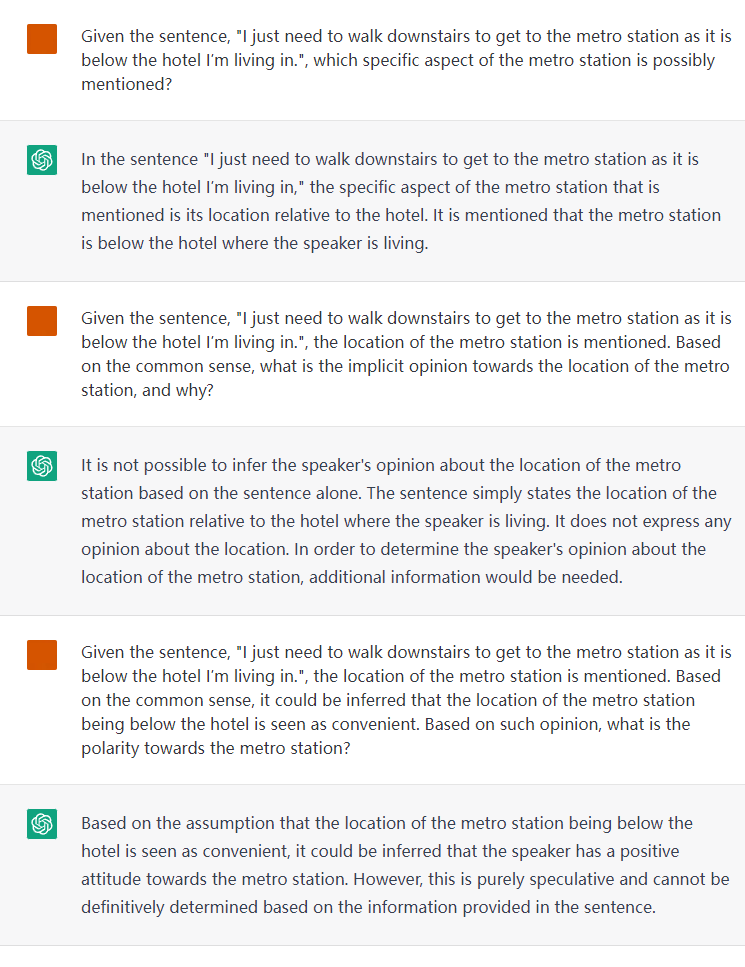
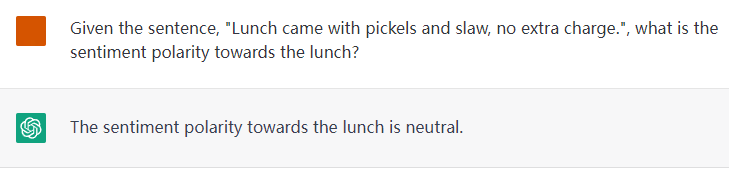
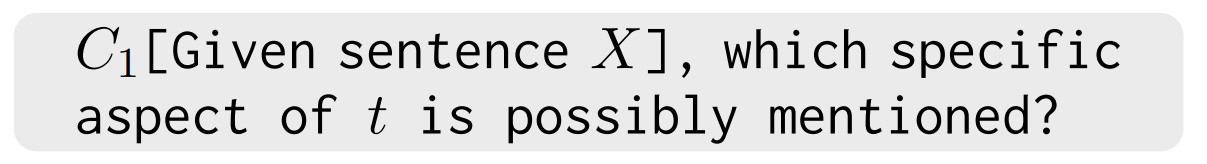Motivation
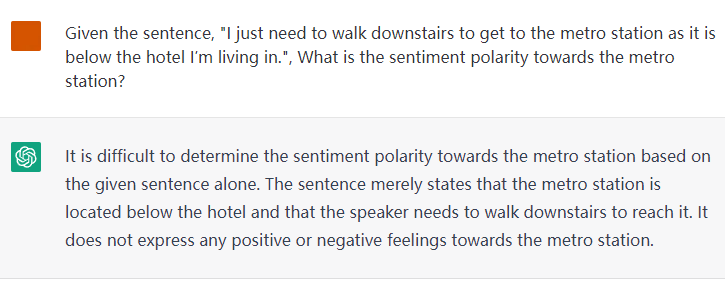
Here is the illustration of detecting the explicit and implicit sentiment polarities towards targets. Explicit opinion expression can help direct inference of the sentiment, while detecting implicit sentiment requires common-sense and multi-hop reasoning.