Previously, I focused on a slightly different research theme, Multimodal Generalist towards Human-level Capacity and Cognition. Even earlier, I focused on Structure-aware Intelligence Learning (SAIL).
Research Statement
Bridging Physical and Mental Worlds toward Human-like Intelligence
Future human-level AI should bridge physical-world grounding with mental-world intelligence, combining unified multimodal capability with cognition, affection, mind, behavior, and social understanding. My research aims to build multimodal AI systems that do not only interact with the external world mechanically, but perceive, reason, generate, and act with increasingly advanced cognitive foundations.
Physical World
Perception, Reasoning, and Generation
Build cross-modal/multimodal systems that can understand, reason over, and generate rich signals across text, speech, audio, image, video, 3D, and 4D settings.
Mental World
Mind, Cognitive, and Social Modeling
Move AI beyond mechanical interaction by modeling cognition, mind, emotion, empathy, mental behavior, and collective intelligence.
Foundation Model
Foundation Multimodal LLMs and Generalists
A unified multimodal foundation model serves as the common substrate that supports both physical-world grounding and mental-world intelligence, enabling generalist perception, reasoning, generation, interaction, and agentic coordination across diverse modalities, paradigm and tasks.
Direction 1
:
Large Multimodal Foundation Models and Agentic Systems
Unified and advanced multimodal foundational systems (LLMs and agents) that coordinate perception, reasoning, generation, and interaction across modalities. Below, I highlight several representative research series that define this direction.

Any-to-Any MLLMs
Unified any-to-any multimodal LLMs that move beyond perception-only systems toward fully interleaved multimodal input-output intelligence.
- NExT-GPT The first unified any-to-any multimodal LLM.
- UniM A benchmark for interleaved any-to-any multimodal understanding and generation.
- Any2Any Workshop The first workshop for this series.
- Awesome Any2Any A collection of resources on Github: paper, datasets and tools.

Unified Vision LLMs
Pixel-level large vision foundation models for understanding, generation, segmentation, editing, and controllable interaction with visual content.
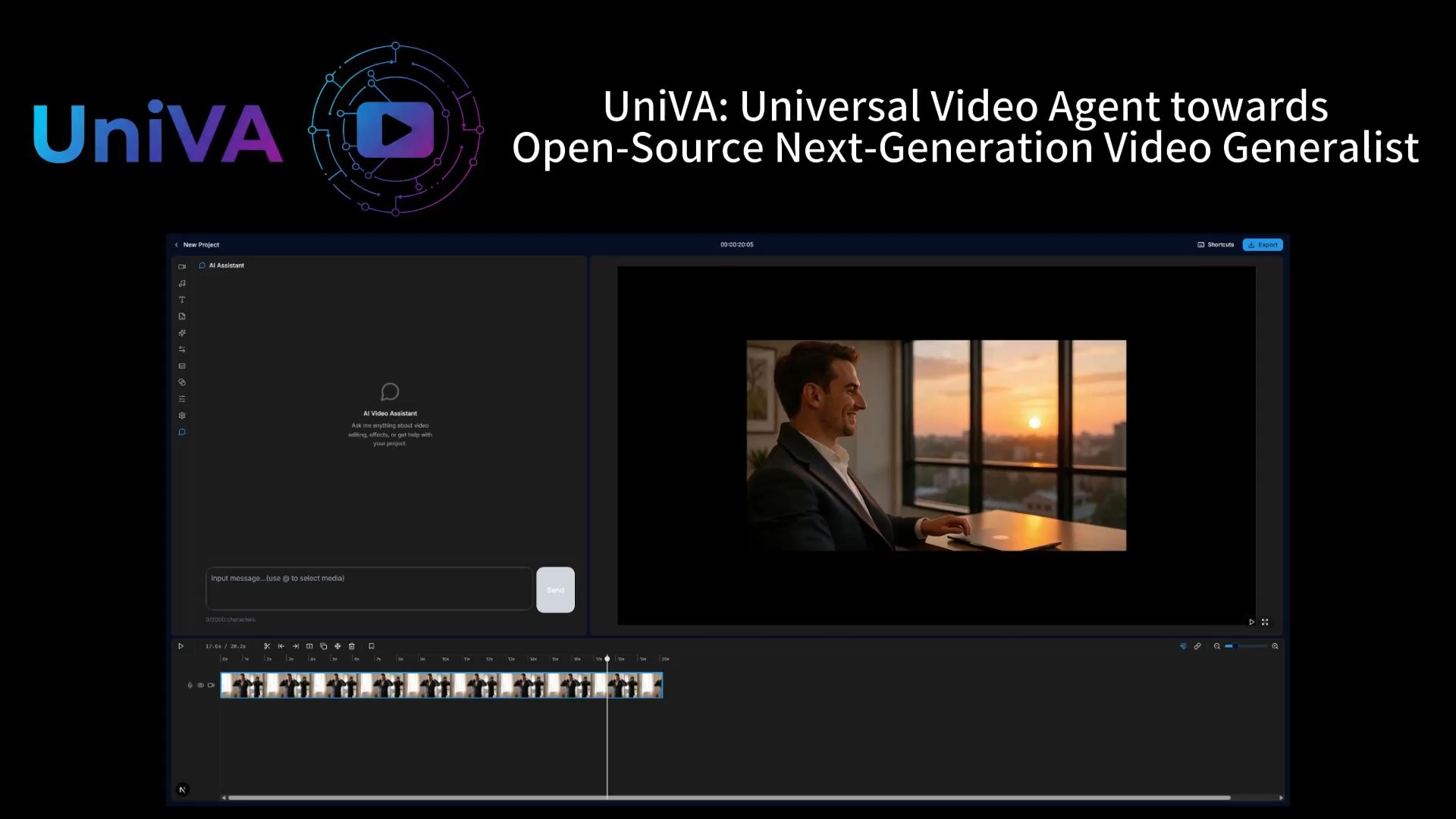
UniVA: Universal Video Agent
A universal video agent that unifies video understanding, editing, tracking, planning, and creation in an automated agentic workflow.
Towards Multimodal Generalist
A research line on building multimodal generalist AI unifies modalities, tasks, paradigms, enabling synergistic perception, reasoning, and generation.
- General-level&General-Bench Evaluation framework measuring progress of multimodal models toward true generalist intelligence.
- Unified-R1 Analyzing-Drafting loop interleaves understanding and generation, improving multimodal reasoning and performance.
- MUCG Workshop The workshop series of MLLM on Unified Comprehension and Generation.
- MLLM Tutorial The first tutorial series of MLLM: From Multimodal LLM to Human-level AI.
Direction 2
:
Cross-modal Comprehension, Reasoning, and Generation
Model the physical world through multimodal understanding, generation, and structured reasoning across text, speech, image, video, 3D, and 4D signals. Below, I highlight several representative research series that define this direction.

Javis: Joint Audio-Video Intelligence
Large generative foundation models for synchronized/joint audio-video generation.
- Javis-DiT A joint audio-video diffusion transformer for synchronized generation.
- Javis-DiT++ A stronger generation model with improved fidelity and temporal coordination.
- Javis-GPT A GPT-style multimodal system for audio-video understanding and generation.
- JAV-CG Workshop The 1st workshop on Joint audio-video comprehension and generation.
- JAV Survey A survey-level synthesis of audio-video foundation modeling and generation.

Video Generation Lab
Video generation research embedding multimodal intent, causal reasoning, and physics for high-quality, faithful, physically consistent synthesis.
- Any2Caption Dense captioning and interpretation for any-conditioned video generation.
- ReaDe A generation line focused on richer control and reasoning in video synthesis.
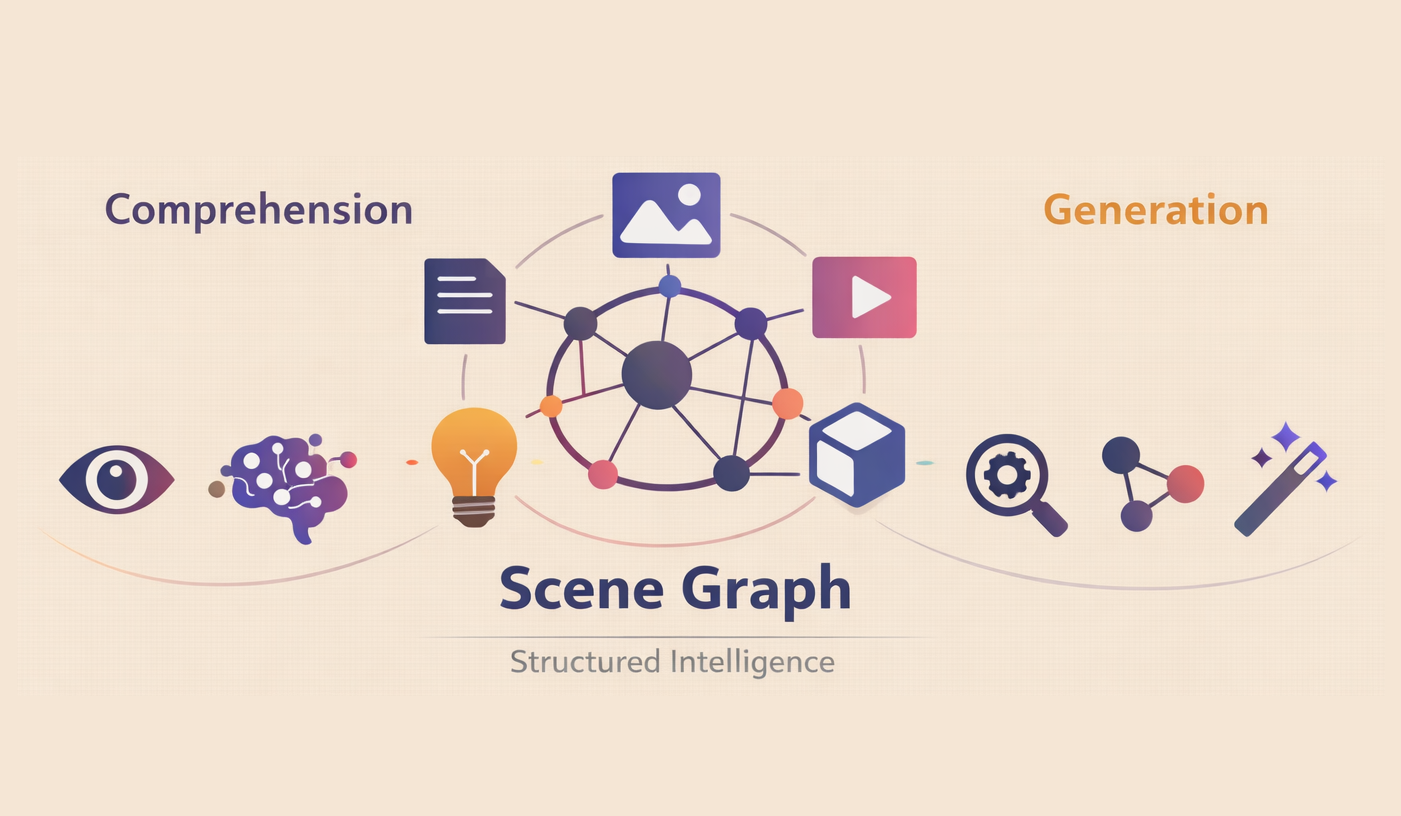
Scene Graph Structure Modeling
Scene graphs provide structured representations enabling multimodal reasoning, generation, controllability, explainability, and generalization across modalities.
- Universal Scene Graph Defines a unified SG representation spanning image, text, video, and 3D modalities.
- Dysen-VDM Enhance temporal dynamics of text-to-video diffusion with dynamical video SG representation.
- LayoutLLM-T2I Enhance fidelity of text-to-image diffusion with layout from LLMs.
- MRE-ISE Fuse visual and textual SGs into a cross-modal graph for information extraction.
- SG4SI Workshop A focal workshop of Scene Graph for Structured Intelligence.
- Scene Graph Survey A comprehensive review of Scene Graph for Structured Intelligence.

Multimodal Reasoning
Line of work around multimodal chain-of-thought reasoning and other projects that connect perception with higher-level cognition.
- Video-of-Thought A video reasoning framework that extends chain-of-thought into temporal visual space.
- MCoT Survey A systematic survey of multimodal chain-of-thought reasoning.
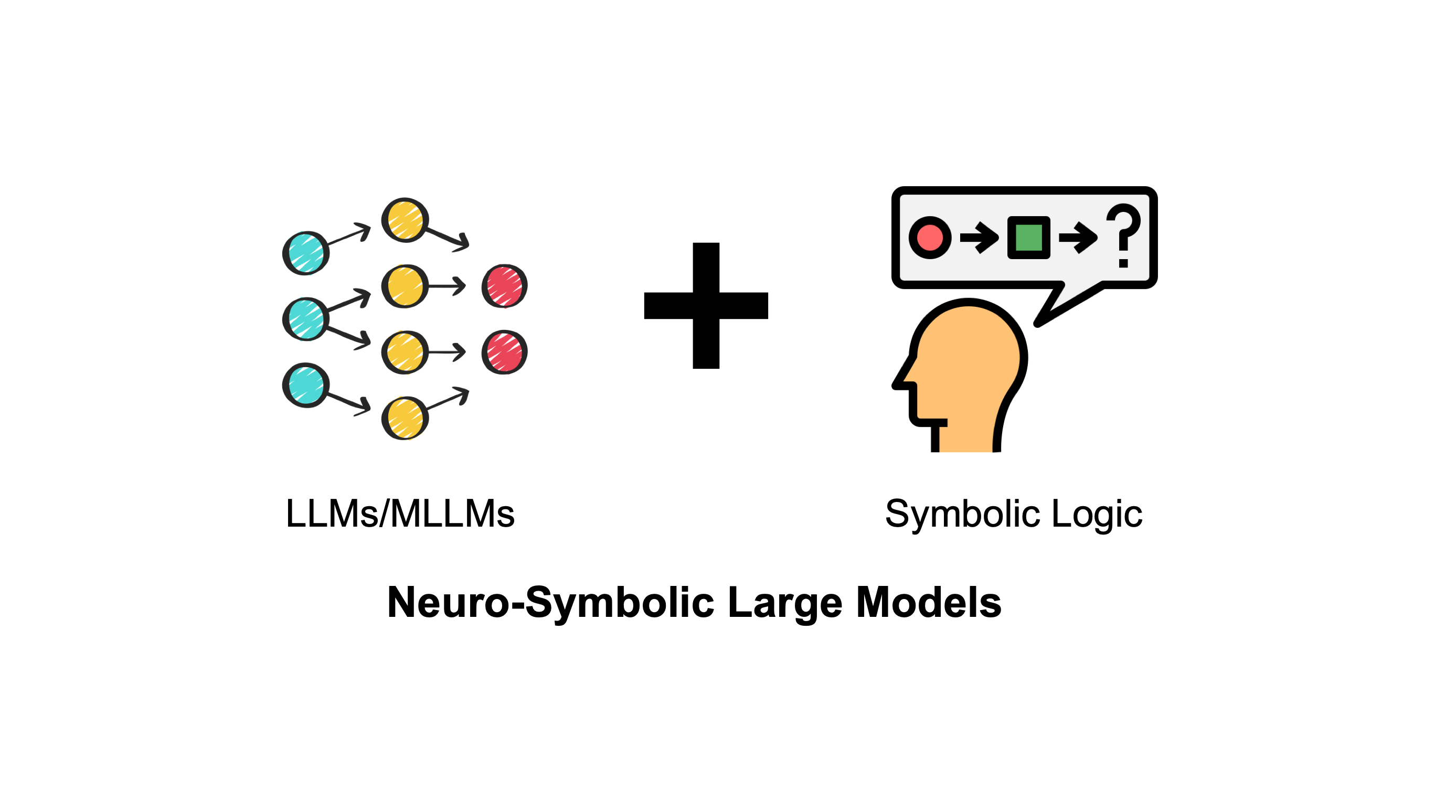
Neuro-symbolic Reasoning
Symbolic structures and logic guide LLM reasoning toward more faithful, controllable, and interpretable decision processes.
- SymbCoT Faithful logical reasoning via symbolic chain-of-thought.
- Aristotle Logic-complete decompose-search-resolve reasoning for complex problems.
- MuSLR A structured framework for more controllable and interpretable logical reasoning.
- LogicReward Reward-driven optimization for stronger logical consistency in LLM reasoning.
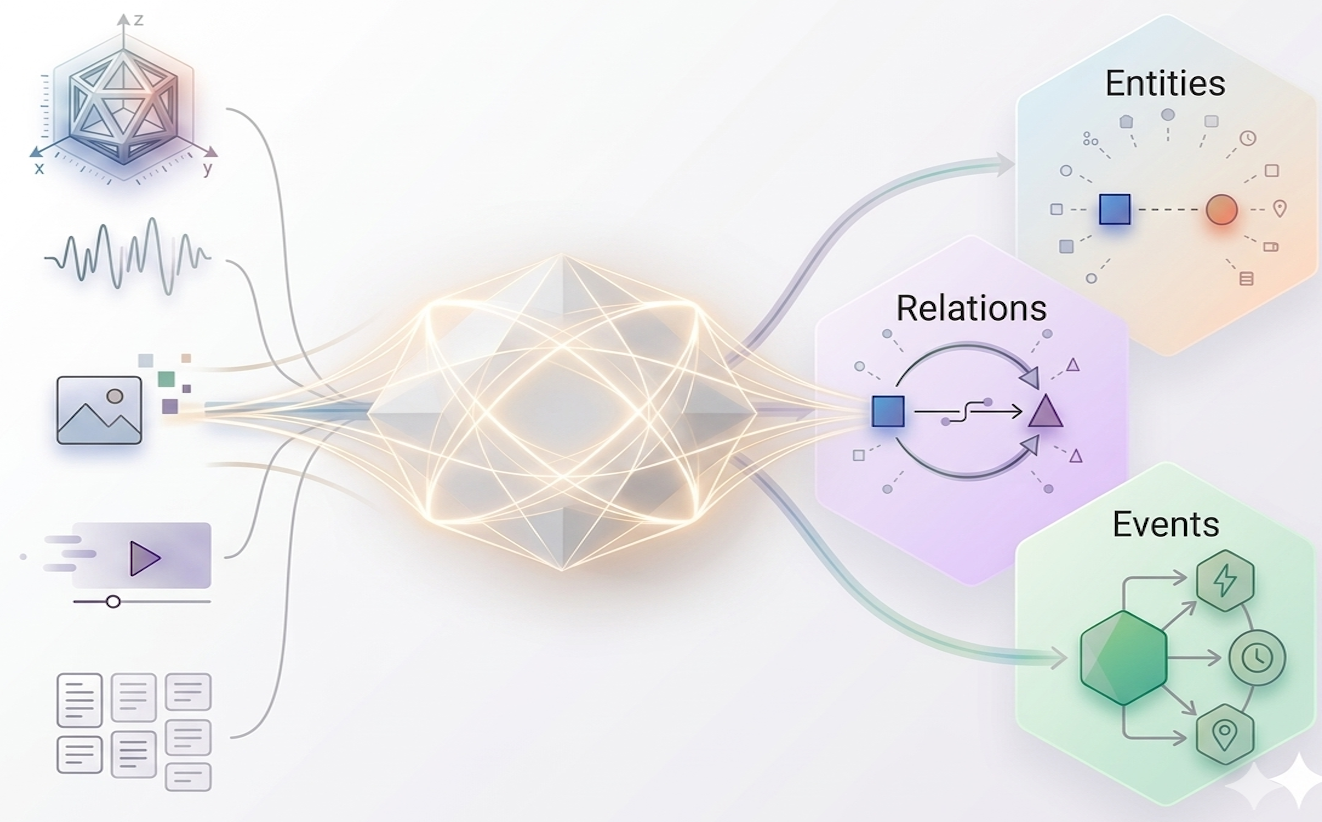
Unified Multimodal Information Extraction
A flexible line of work around multimodal chain-of-thought reasoning and other projects that connect perception with higher-level cognition.
- LasUIE Latent structure-aware universal IE improves entity, relation, and event extraction via unified generative modeling.
- SpeechEE Speech-native event extraction benchmark with end-to-end model operating directly on audio.
- XNLP An interactive platform enabling unified structured NLP across tasks with scalable, interpretable single-model interface.
- SpeechEE Speech-native event extraction benchmark with end-to-end model operating directly on audio.
- XLLM The 1st workshop on LLMs and structure modeling.
- EE Survey Event Extraction in LLMs: a holistic view of method, modality, and future.
- SRL Survey Semantic Role Labeling: A Systematical Survey.
Direction 3
:
Mental-World Modeling: Affect, Cognition, Behavior, and Social Intelligence
Model how AI individuals can feel, infer, empathize, and behave with richer cognitive and social awareness rather than interacting with the world in a purely mechanical manner. Below, I highlight several representative research series that define this direction.

Unified Cross-modal Affective & Empathetic Computing
UniCAE unifies multimodal affective understanding and generation, enabling empathetic AI across language, speech, vision, and 3D.
- DiaASQ The first benchmark of Conversational Aspect-based Sentiment Quadruple Analysis.
- PanoSent The first benchmark of Multimodal Conversational Aspect-based Sentiment Quadruple Analysis.
- EmpathyEar An open multimodal empathetic chatbot that turns text-only ERG into embodied avatar interaction."
- MERG The first benchmark for multimodal empathetic response generation.
- Emotional 3D Avatar Emotion-aware avatar generation for expressive multimodal interaction.
Cognition
Mental World Modeling
Under Progressing
Mental World Modeling
Mental world modeling integrates physical dynamics and human cognitive-social states for comprehensive, interactive intelligence modeling.
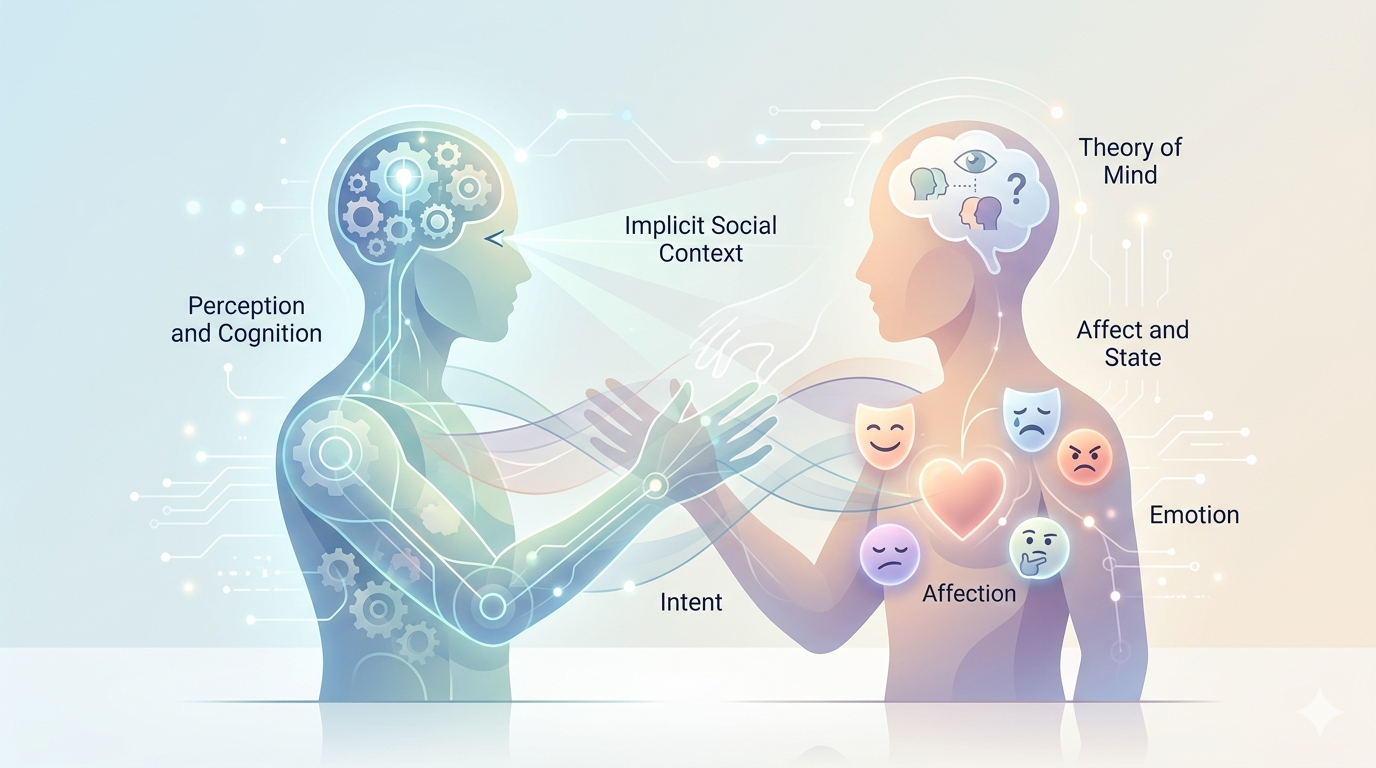
Cognition-driven Affective Computing
Cognition-driven affective computing integrates perception, Theory-of-Mind, and social context and mental state to reason implicit emotions and hidden intentions.
- THOR The first chain-of-thought reasoning framework for implicit sentiment analysis.
- HitEmotion Theory-of-Mind-guided multimodal emotion reasoning with benchmark and pipeline tracking mental states.
- CogMAEC Workshop A workshop for cognition-oriented multimodal affective and empathetic computing.
Social Intelligence
Social & Behavioral Intelligence
Under Progressing
Social & Behavioral Intelligence
Large-scale modeling of cognition, mind, behavior, and social intelligence, including simulations of individuals and groups.